Maximizing GEN-AI Performance: A Guide to Data Preprocessing Terms

🚀 Passionate Data Enthusiast and Problem Solver 🤖
🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021)
👨💻 Professional Experience:
- Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving.
- Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow.
- Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra.
📈 Skills Highlights:
- Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps.
- Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python.
- Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency.
💡 Initiatives:
- Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts.
- Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully.
🌏 Next Chapter:
- Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities.
- Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews.
🔗 Let's Connect!
- Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring.
- Reach out for a conversation on Data Science, technology, or potential collaborations!
- Email: naiksaurabhd@gmail.com
Introduction:
In the realm of AI-driven solutions, the quality of data preprocessing plays a crucial role in determining the effectiveness and efficiency of models. However, data preprocessing for GENAI, with its diverse range of document types and extraction variability, poses unique challenges. From standardization needs to the extraction of metadata insights, each step in the preprocessing pipeline demands careful consideration and strategic implementation. In this blog, we delve into the intricacies of data preprocessing for GENAI, exploring the challenges, strategies, and benefits associated with each stage of the process.
Why is Data Preprocessing Hard?
Content Cues:
The diversity in document types introduces variability in content cues, necessitating adaptable preprocessing strategies.
Standardization Need:
The heterogeneous nature of documents requires standardization to ensure consistency across data sources.
Extraction Variability:
Different document types demand multiple strategies for data extraction, adding complexity to the preprocessing pipeline.
Metadata Insights:
Understanding document structures is essential for extracting valuable metadata, driving insights and decision-making.
Normalizing Data Documents:
Normalization serves as the cornerstone of data preprocessing, facilitating the conversion of diverse document formats into a unified framework. By standardizing document structures, normalization streamlines subsequent preprocessing steps and enables efficient data analysis.
Benefits of Normalization:
Removal of Unwanted Elements:
Normalization aids in the elimination of irrelevant content, enhancing data quality.
Consistent Processing:
Standardized formats enable uniform processing across diverse document types, reducing complexity and computational overhead.
Cost-Efficient Computation:
Normalization minimizes the need for specialized preprocessing techniques, allowing for cost-effective experimentation and analysis.
Data Serialization:
Serialization enables the preservation and reuse of preprocessed data, facilitating reproducibility and scalability in AI workflows. By storing processed results, serialization enhances workflow efficiency and supports iterative model development.
Hybrid Search:
To address the limitations of semantic search, hybrid search integrates similarity-based filtering with metadata insights, delivering more comprehensive and relevant search results. By leveraging both semantic and metadata-driven approaches, hybrid search enhances search accuracy and user experience.
Chunking:
Chunking involves breaking down large documents into smaller pieces, optimizing data input for models like LLMs with limited context windows. By partitioning documents into manageable chunks, chunking enhances model performance and reduces computational overhead.
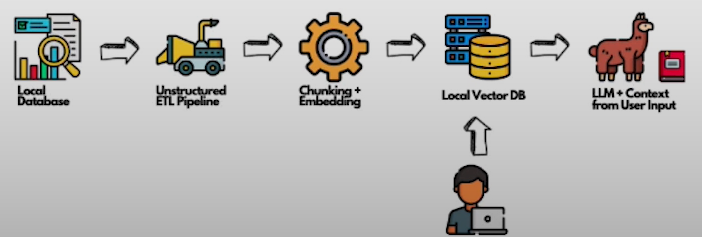
Summary:
Data preprocessing forms the foundation of AI-driven solutions like GENAI, enabling efficient data management, analysis, and model training. By addressing challenges such as content cues, standardization needs, and extraction variability, preprocessing pipelines can unlock the full potential of AI systems. From normalization and serialization to hybrid search and chunking, each preprocessing step contributes to enhancing model performance and delivering actionable insights. As we continue to refine and optimize data preprocessing strategies, the journey towards maximizing AI performance in domains like GENAI remains an exciting and transformative endeavor.




