

Introduction:
Support Vector Machines (SVM) are a powerful class of machine learning algorithms renowned for their ability to handle complex classification and regression tasks. Whether you're building a spam filter, recognizing handwritten characters, or diagnosing diseases, SVMs offer an indispensable tool in your data science toolkit. In this comprehensive blog post, we'll delve into the inner workings of SVMs, explore their core concepts, and understand how they can be applied to a wide range of real-world problems.
The Kernel of SVMs:
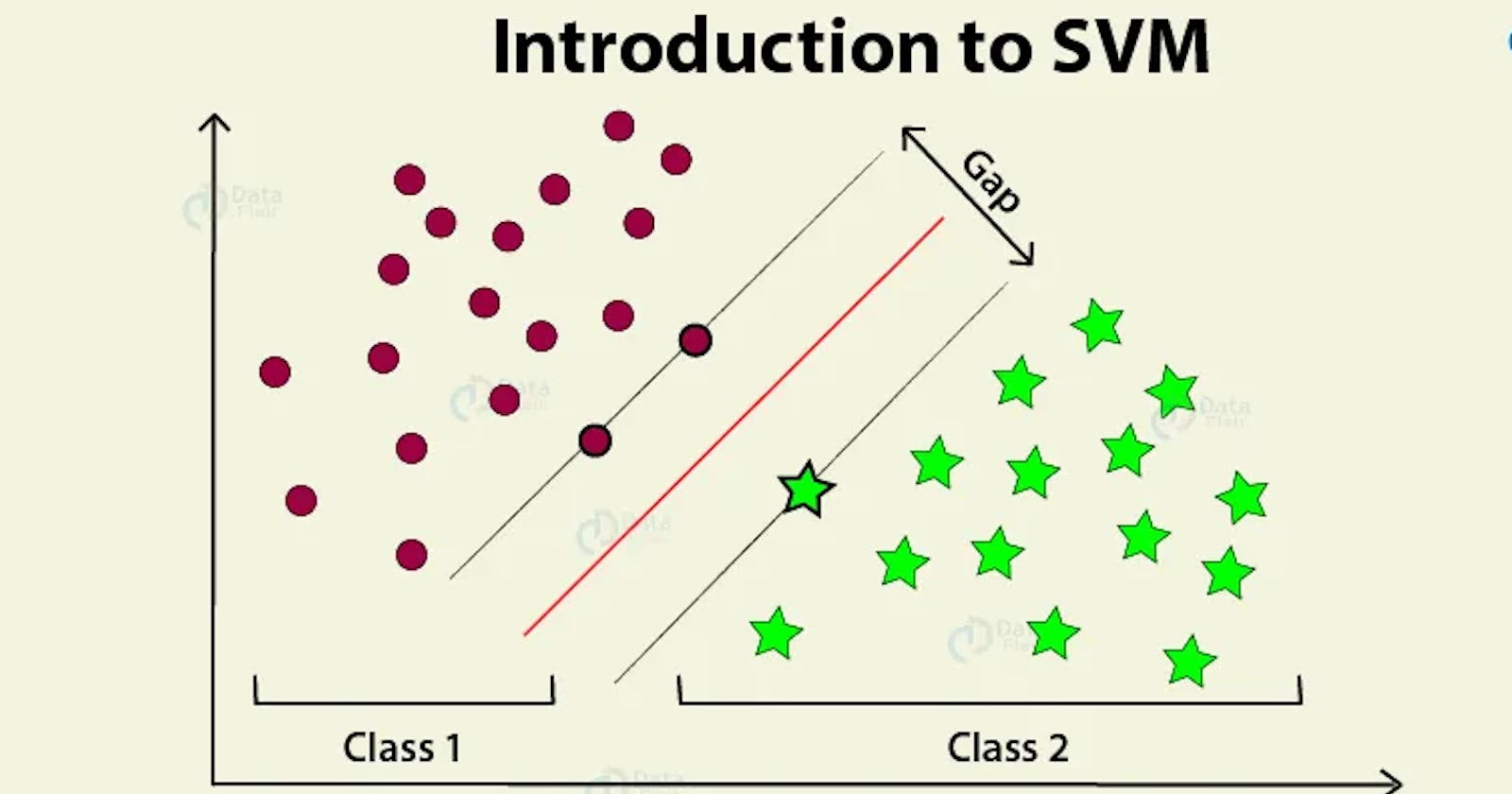
At the heart of SVMs lies the concept of finding an optimal hyperplane—a decision boundary that best separates data points belonging to different classes. SVMs excel in scenarios where the data is not linearly separable, thanks to a technique known as the kernel trick. Key elements of SVMs include:
Margin Maximization:
SVMs strive to maximize the margin—the distance between the decision boundary and the nearest data points of each class. This results in a robust model that generalizes well to unseen data. The data points closest to the decision boundary are called support vectors, hence the name "Support Vector Machines."
Hyperplane and Non-linearity
For linearly separable data, a linear hyperplane does the job. However, in cases where the data is more complex and non-linear, SVMs utilize the kernel trick. Kernels transform the data into higher-dimensional spaces, making it easier to find a hyperplane that separates the classes.
The Kernel Trick
The kernel trick is a brilliant concept that empowers SVMs to handle non-linear data. Instead of explicitly mapping data into a higher-dimensional space, which can be computationally expensive, kernels allow SVMs to operate in the original feature space while reaping the benefits of higher-dimensional representations.
Polynomial Kernel
One popular kernel is the polynomial kernel, which implicitly computes the dot product of data points in a higher-dimensional space, thereby capturing non-linear relationships.
Radial Basis Function (RBF) Kernel
The RBF kernel, also known as the Gaussian kernel, is another widely used option. It transforms data into an infinite-dimensional space, creating a smooth transition between classes in non-linear datasets.
SVM for Classification
In classification tasks, SVMs determine the class labels for data points. Here's how it works:
Feature Space Mapping: The input data is transformed into a higher-dimensional feature space using a chosen kernel (e.g., polynomial or radial basis function).
Hyperplane Search: SVM searches for the hyperplane that maximizes the margin while minimizing classification errors.
Classification: New data points are mapped into the same feature space and classified based on which side of the hyperplane they fall on.
SVM for Regression
SVMs are not limited to classification; they can perform regression as well. In regression tasks, SVMs predict continuous target values. Here's how:
Mapping and Hyperplane: Similar to classification, the input data is mapped into a higher-dimensional space, and a hyperplane is found.
Regression Prediction: Instead of class labels, SVMs predict the target values. The predicted value is based on the distance between the data point and the hyperplane.
Visualizing the SVM:
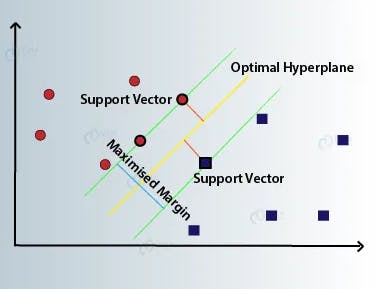
The visual representation of SVM showcases the idea of finding the optimal hyperplane and the role of support vectors. This intuitive approach, coupled with the kernel trick's power, forms the foundation of SVM's classification and regression capabilities.
Conclusion
Support Vector Machines are a cornerstone of machine learning, tackling complex problems with elegance and precision. By grasping the core principles, understanding kernel functions, and learning to apply SVMs to classification and regression tasks with the kernel trick, you unlock a powerful tool for your data analysis endeavors. Whether you're dealing with structured or unstructured data, SVMs stand as a formidable ally, ready to help you conquer diverse machine learning challenges. So, embrace the world of SVMs, and let the power of support vectors and kernels guide your data-driven journey.