Discovering Patterns with Precision: The DBScan Algorithm

🚀 Passionate Data Enthusiast and Problem Solver 🤖
🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021)
👨💻 Professional Experience:
- Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving.
- Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow.
- Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra.
📈 Skills Highlights:
- Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps.
- Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python.
- Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency.
💡 Initiatives:
- Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts.
- Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully.
🌏 Next Chapter:
- Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities.
- Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews.
🔗 Let's Connect!
- Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring.
- Reach out for a conversation on Data Science, technology, or potential collaborations!
- Email: naiksaurabhd@gmail.com
Introduction:
Density-Based Spatial Clustering of Applications with Noise, or DBScan for short, is a versatile clustering algorithm that excels in finding clusters of varying shapes and sizes within datasets. Whether you're uncovering hidden patterns in geographical data or segmenting customers based on behavior, DBScan offers a powerful tool for your data exploration arsenal. In this blog post, we'll dive deep into the DBScan algorithm, elucidate key concepts, and explore its practical applications.
Key Terms in DBScan
Before delving into DBScan's inner workings, let's clarify essential terms:
Epsilon (\(\epsilon\)): This parameter defines the radius of a neighborhood around each data point. It determines which nearby points are considered part of the same cluster.
Core Points: Core points are the central points within clusters. A data point becomes a core point if there are at least "min_samples" data points (including itself) within an epsilon radius.
Border Points: Border points are part of a cluster but not core points themselves. They are within an epsilon radius of a core point but do not meet the "min_samples" criterion for core point status.
Noise: Noise points, also known as outliers, are data points that do not belong to any cluster. They are typically isolated from other data points and do not meet the conditions to be core or border points.
DBScan Algorithm in Action
The DBScan algorithm starts with two essential hyperparameters: epsilon\((\epsilon)\) and "min_samples." Here's a step-by-step breakdown of the algorithm:
Random Point Selection: Begin by selecting a random data point from the dataset.
Epsilon Neighborhood: Draw a circle around the selected point with a radius of \((\epsilon)\). Any data points within this circle are considered part of the same cluster.
Core Point Identification: If the number of data points inside the circle (including the selected point) is equal to or greater than "min_samples," the selected point becomes a core point.
Expanding the Cluster: Explore the other data points within the circle, and for each data point, repeat steps 2 and 3. This process continues until all data points within the cluster are identified.
Border Points: Any data points within the cluster that are not core points become border points.
Noise Detection: Data points that do not belong to any cluster are classified as noise points or outliers.
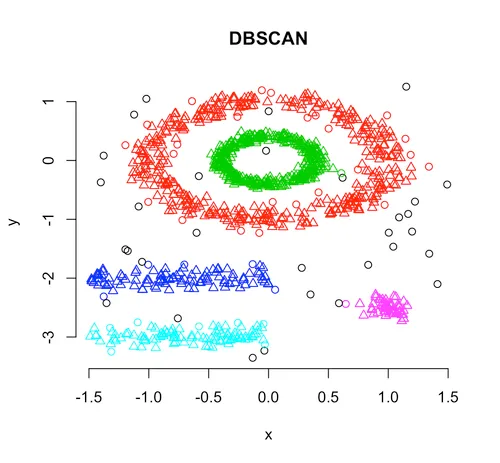
Advantages of DBScan
DBScan offers several advantages for clustering tasks:
Robust to Irregular Cluster Shapes: DBScan can identify clusters of various shapes and densities, making it suitable for complex datasets.
Noise Detection: It excels at detecting outliers, making it useful for anomaly detection.
No Need to Specify k: Unlike some other clustering algorithms, DBScan does not require you to predefine the number of clusters.
Limitations and Considerations
Sensitive to Hyperparameters: The performance of DBScan can be affected by the choice of epsilon \(\epsilon\) and min_samples. Tuning these hyperparameters is crucial.
Uneven Cluster Sizes: DBScan may struggle with clusters of significantly different sizes.
Initial Point Sensitivity: The choice of the starting point can impact cluster formation, potentially leading to different results.
Practical Applications
DBScan finds application in various domains, including:
Geographical Data Analysis: Identifying clusters of locations with similar characteristics.
Anomaly Detection: Detecting unusual patterns or outliers in cybersecurity or fraud detection.
Customer Segmentation: Grouping customers with similar purchasing behavior.
Image Processing: Identifying connected components in images.
Conclusion
DBScan, with its ability to discover clusters of arbitrary shapes and robust noise detection, is a valuable addition to your clustering toolkit. By understanding its core principles and the role of hyperparameters, you can leverage DBScan for a wide range of data analysis tasks. While it offers flexibility and versatility, it's essential to fine-tune hyperparameters and be mindful of potential challenges. So, embrace the power of density-based clustering with DBScan and embark on a journey of data exploration and insights.




