Cracking the Code: Understanding Encoder-Decoder Architecture and Distance Measures for Word Embeddings with Python

🚀 Passionate Data Enthusiast and Problem Solver 🤖
🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021)
👨💻 Professional Experience:
- Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving.
- Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow.
- Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra.
📈 Skills Highlights:
- Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps.
- Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python.
- Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency.
💡 Initiatives:
- Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts.
- Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully.
🌏 Next Chapter:
- Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities.
- Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews.
🔗 Let's Connect!
- Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring.
- Reach out for a conversation on Data Science, technology, or potential collaborations!
- Email: naiksaurabhd@gmail.com
Introduction:
Word embeddings, a cornerstone of natural language processing (NLP), provide a means to represent words in a machine-understandable format by capturing their semantic meaning. In this technical blog, we delve into the encoder-decoder architecture for generating word embeddings and explore different distance measurement techniques to quantify the similarity between embeddings. With Python code examples, we elucidate the process of implementing these methodologies, offering insights into their practical applications.
Encoder-Decoder Architecture for Word Embeddings:
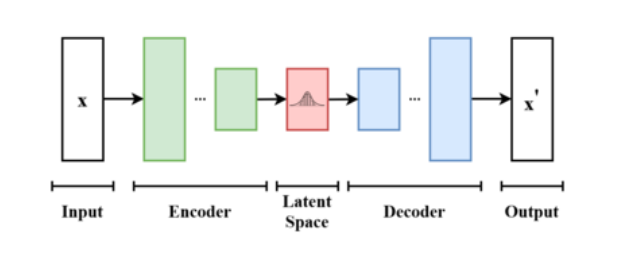
The encoder-decoder architecture is pivotal in generating word embeddings, enabling the transformation of textual data into numerical representations. The process involves loading the dataset, setting hyperparameters for the neural network, defining encoder and decoder layers, and training the model. Subsequently, the trained embedding model is utilized for testing, facilitating the extraction of meaningful representations from textual inputs.
Distance Measurement Techniques:
Euclidean Distance:

Euclidean distance calculates the shortest distance between two vectors in the multi-dimensional space.
Python code example:
import numpy as np
def euclidean_distance(vector1, vector2):
return np.linalg.norm(vector1 - vector2)
Manhattan Distance:
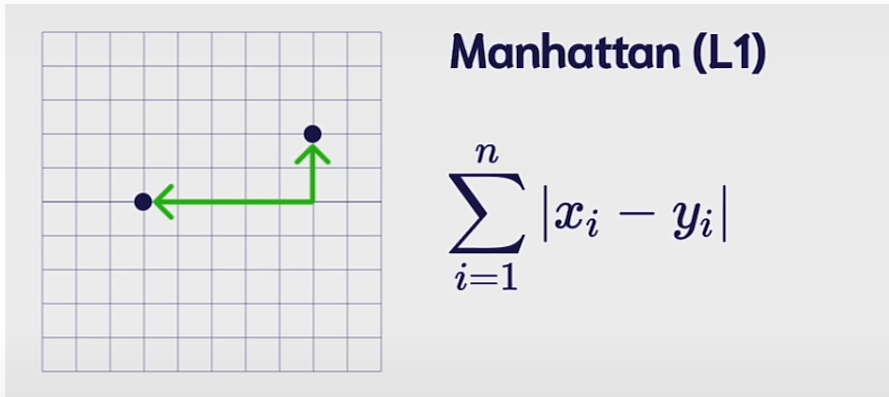
Manhattan distance measures the distance between two points as if we are only moving along one axis at a time.
Python code example:
def manhattan_distance(vector1, vector2):
return np.sum(np.abs(vector1 - vector2))
Dot Product:
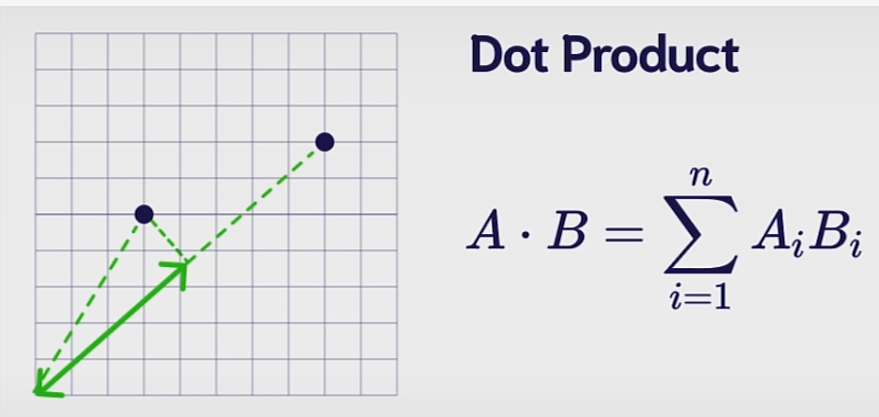
Dot product measures the projection of one vector onto the other, providing insight into their alignment.
Python code example:
def dot_product(vector1, vector2):
return np.dot(vector1, vector2)
Cosine Distance:
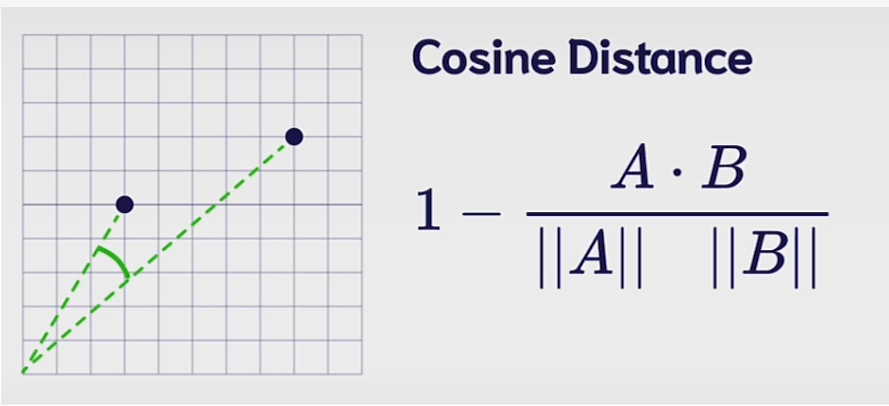
Cosine distance quantifies the similarity between vectors based on the cosine of the angle between them.
Python code example:
def cosine_distance(vector1, vector2):
return 1 - np.dot(vector1, vector2) / (np.linalg.norm(vector1) * np.linalg.norm(vector2))
Conclusion:
Word embeddings play a crucial role in NLP tasks, facilitating efficient representation and analysis of textual data. Through the encoder-decoder architecture, textual inputs are transformed into vector embeddings, enabling computational processing. Furthermore, by employing various distance measurement techniques such as Euclidean distance, Manhattan distance, dot product, and cosine distance, we can quantify the similarity between embeddings, thereby enhancing the efficacy of NLP models. With the provided Python code snippets, readers can gain practical insights into implementing these methodologies and harnessing the power of word embeddings in their projects.




