

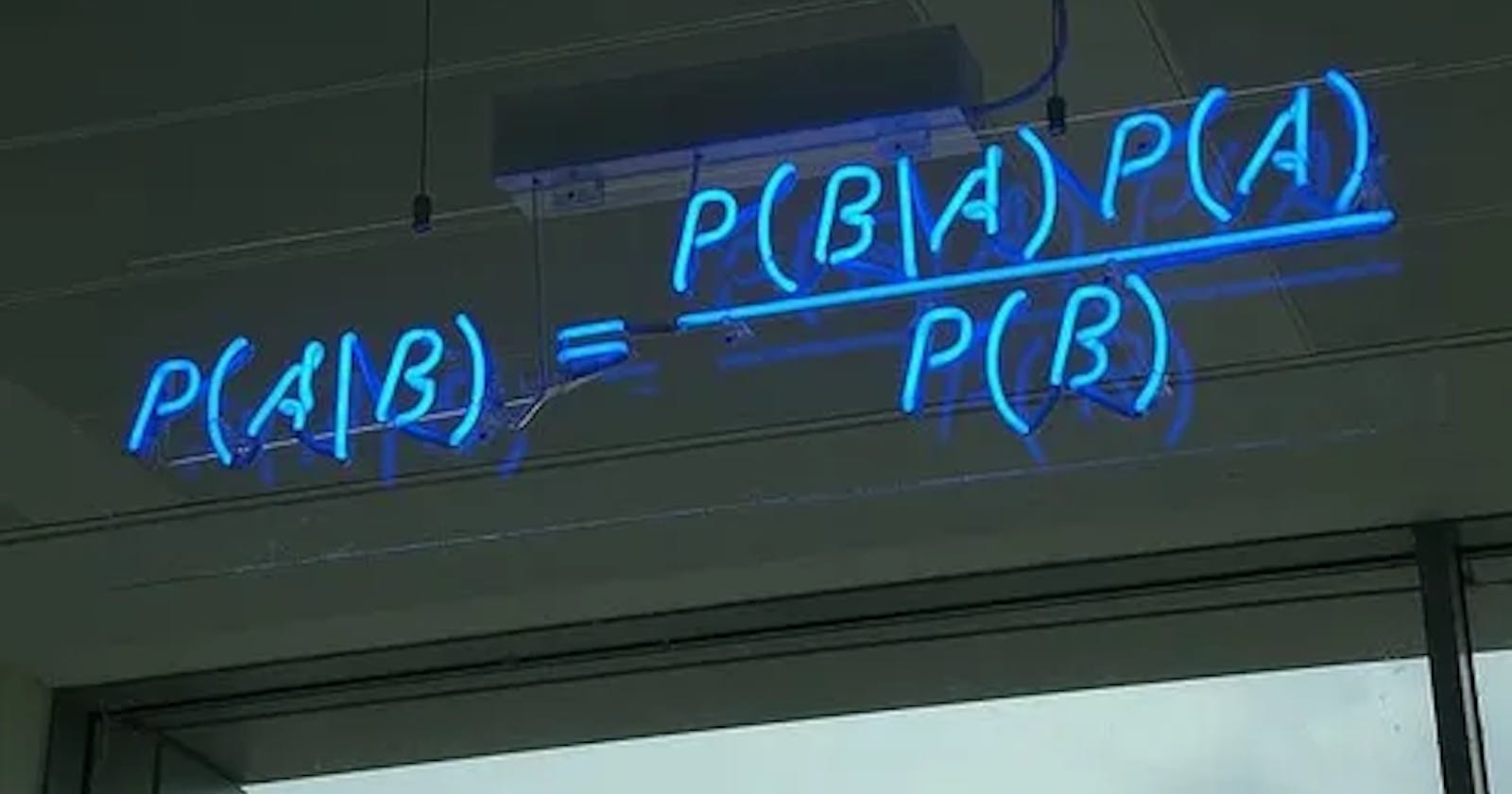
Introduction:
In the vast landscape of machine learning algorithms, one approach stands out for its simplicity, effectiveness, and versatility: Naive Bayes. Behind its humble façade lies a powerful tool for classification and probabilistic modeling. In this blog post, we'll embark on a journey through the world of Naive Bayes, exploring its underlying principles, applications, and why it's considered a go-to method in many data science tasks.
The Bayes' Theorem:
At the heart of Naive Bayes lies the Bayes' theorem, a fundamental concept in probability theory and statistics. The theorem provides a way to update the probability of a hypothesis based on new evidence. In the context of machine learning, it helps us make predictions and classifications based on observed data.
The Bayes' theorem is expressed as:
\( P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} \)
( P(A|B) ): The probability of event A occurring is given that event B has occurred.
( P(B|A) ): The probability of event B occurring given that event A has occurred.
( P(A) ) and ( P(B) ): The probabilities of events A and B occurring independently.
The Naive Assumption:
The "Naive" in Naive Bayes comes from the assumption of conditional independence between features. In other words, it assumes that the presence or absence of one feature is independent of the presence or absence of any other feature, given the class label. This simplifying assumption greatly reduces computational complexity and makes Naive Bayes a fast and efficient algorithm.
Types of Naive Bayes:
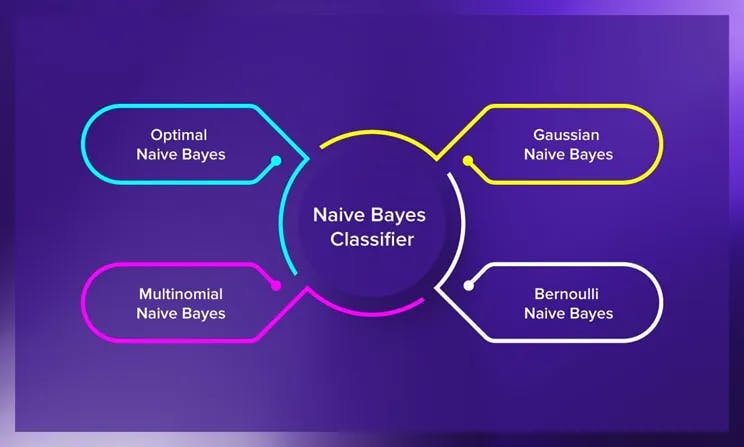
There are three common types of Naive Bayes classifiers:
Gaussian Naive Bayes: This variant is used when the features follow a Gaussian distribution. It's suitable for continuous data.
Multinomial Naive Bayes: Ideal for discrete data, such as text, where the features represent the frequency of words.
Bernoulli Naive Bayes: Suited for binary data, where features are either present (1) or absent (0).
Optimal Naive Bayes: It's particularly effective for text and categorical data, assuming feature independence given the class and providing robust results with efficient computations.
Applications of Naive Bayes:
Naive Bayes finds applications across various domains:
Text Classification: It's widely used for spam detection, sentiment analysis, and topic classification in natural language processing (NLP).
Email Filtering: Naive Bayes helps filter emails into spam and non-spam categories.
Medical Diagnosis: It aids in diagnosing diseases based on patient symptoms and test results.
Recommendation Systems: Naive Bayes can be used to build recommendation systems that suggest products or content based on user behavior.
News Categorization: It classifies news articles into topics like sports, politics, or entertainment.
Advantages of Naive Bayes:
Simplicity: Naive Bayes is easy to implement and understand, making it an excellent choice for quick and efficient classification tasks.
Efficiency: It works well with high-dimensional data and is computationally efficient.
Interpretability: Naive Bayes provides transparency in decision-making, as you can see the probabilities of each class.
Good Baseline: It serves as a strong baseline model for text classification tasks, often outperforming more complex algorithms.
Limitations of Naive Bayes:
Independence Assumption: The assumption of feature independence may not hold in real-world datasets, leading to suboptimal performance.
Limited Expressiveness: Naive Bayes may not capture complex relationships between features.
Sensitivity to Data: It can be sensitive to the quality and quantity of data, particularly for rare events.
Conclusion:
Naive Bayes, despite its simplifying assumptions, continues to be a valuable tool in the machine learning toolkit. Its speed, efficiency, and effectiveness in various applications make it a compelling choice for classification tasks, particularly in scenarios where interpretability and simplicity are paramount. So, the next time you need a quick and reliable classifier, consider the power of Naive Bayes to make accurate predictions based on probability and evidence.